(This page is under construction.)
Table of Contents
Introduction
Insofar as the Space Shuttle is concerned, the Virtual AGC
Project's present goals — or if you'd prefer, my goals —
are the following:
- To provide the complete source code for the software for the
most-significant of its onboard computer systems, to the extent
allowed by U.S. law.
- To provide all of the official documentation needed to
understand that software and to work with it. See the References.
- To provide development tools suitable for working with the
software source code, and in particular for compiling/assembling
it into executable form.
- To provide an emulator suitable for running that executable
code.
- For the emulator to be integrated into space-flight simulation
systems such as Orbiter+SSU or FlightGear.
In essence, we'd like to do the same kinds of things for the
Space Shuttle's onboard computers, and in particular the
computers' software, as we have done for Apollo's onboard computer
systems and software.
I don't pretend to be putting together an "everything
about the Space Shuttle" site. If you want to know about the
Space Shuttle's Main Engines (SSME) or Reaction Control System
(RCS), or hear marvelous facts such as the maximum payload size
being a 15×60 foot cylinder weighing 65,000 pounds, then this is not
the place to look. (But that's big, isn't it?
I never knew.)
Now, there are various nuances to the statements above, such as
whether access to source code must be restricted in some ways,
rather than being freely available. And by "the" source
code, do I mean all revisions? Do I mean for all
components of the system? And by "the" development tools, do
I mean the original ones, or do I mean partial work-alikes?
And by emulation, do I mean emulation of the entire stack of code,
or just for some restricted portion of it? And besides
which, how do I really know which documents may be relevant to
these matters and which may be completely irrelevant?
For example, although I explicitly said above that this isn't
the site to come to if you want to learn about engines (SSME), the
engines were in fact controlled by a dedicated controller
containing two redundant Honeywell
HDC-601 digital computers ... so shouldn't those computers
and their software be covered here?
Answers to those questions will become clear in the sections
below ... or at least, clearer than they are now. There are
a lot of gray areas. And I don't pretend to know all of the
answers yet, so we may need to await future events to have a
more-complete picture. But there aren't necessarily unique,
permanently-correct answers anyway. One thing I can say
unequivocally is that integration into space-flight simulation
systems is my hope rather than anything that I'll actively pursue
personally; integration is the prerogative of the developers of
those space-flight simulators, rather than mine, if they feel it's
worthwhile for them. But it's a bit premature to worry about
that yet.
The upshot is that my explanation of the Shuttle's computer
systems will by necessity be rather limited. The system is
simply too complex, and there are too many resources already
available on the web for me to suppose that a presentation by a
johnny-come-lately like me would be worthwhile or even interesting
about a topic this big. Perhaps the best place to get a
general introduction would be Chapter
4, "Computers in the Space Shuttle Avionics System", of James
Tomayko's Computers in Spaceflight: The NASA Experience,
but there are numerous other documents in our Shuttle
Library to provide more detail.
With that said, here's a brief synopsis. As with any
engineering system of substantial complexity, prepare to descend
into acronym hell!
The portion of the Shuttle's full avionics system which primarily
concerns us is the Data Process System (DPS), which
includes the General Purpose Computers (GPC), the crew
interface (display and keyboards), the mass-memory units, and the
data-bus network interconnecting all of them. Here's a
diagram, swiped from the aforementioned Computers in
Spaceflight, that gives a very high-level view of the system
architecture:
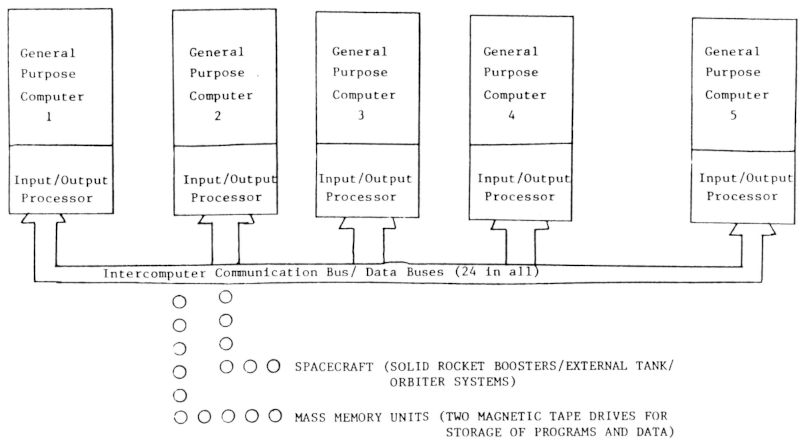
As you can see, there were five separate GPCs. Each of the
GPCs on later flights was an AP-101S computer, designed and
manufactured by IBM's Federal Services Division (as were the
Apollo LVDC or Gemini OBC, though the GPC was not similar to
them in any noticeable way). Although I may not talk about
the AP-101S much, it's worth mentioning that it was a kind of
embedded version of the IBM System/360 mainframe, in that it
shared roughly the same assembly language, known as
Basic
Assembly Language (BAL).
Aside: To be perfectly
pedanticaccurate, the GPCs were originally
AP-101B computers. The AP-101S is an upgrade of the
AP-101B, replacing 416KB of core memory with 1024KB of
semiconductor (CMOS) memory, and possibly other improvements
that I've so far not been able to identify for certain,
though there are various machine-code instructions that I
believe were newly-added in the AP-101S. The upgrade
effort began in 1989, and was first flown in 1991 on STS-37
with software version OI-8F. More on the topic of
flight-software versioning will appear later.
Four of the GPCs nominally redundantly ran
identical
software, known as the
Primary Flight Software (PFS)
atop the
Flight Control Operating System (FCOS).
PFS and FCOS together are collectively referred to as the
Primary
Avionics Software Subsystem (PASS).
Aside: In spite of this
technical distinction between the acronyms PFS and PASS, I
find in practice (and have been chided by veterans of the
Shuttle project) that the term PASS was always used in
preference to PFS. In other words, people speak of
PASS vs BFS rather than PFS vs BFS, and stare at you blankly
if you mention PFS to them. Since that is the common
usage, I'm going to adopt it throughout the remainder of
this article, and will not bull-headedly use the acronym PFS
(even though I think it's technically correct) even where
the distinction vs PASS is significant.
Nominally, the behaviors of these four copies of FCOS were
synchronized ... not on a CPU-cycle by CPU-cycle basis, but to
the extent that inputs to the GPCs from the spacecraft, as well
as commands output from the GPCs to the spacecraft, occurred at
the same time. In particular, the fact that outputs from
the GPCs were synchronized allowed detection if one of the GPCs
was behaving abnormally. I say they did this "nominally",
because this extreme level of redundancy was warranted only
during critical flight phases ... in particular, during ascent
and reentry. During the more-leisurely phases of the
mission, if additional computing power was needed, the four
principal GPCs did not necessarily need to run identical,
redundant software.
The fifth GPC instead ran the
Backup Flight Software (BFS),
created entirely separately from PASS in a clean-room
fashion. This fifth GPC served roughly the same purpose in
the Shuttle as the Abort Guidance System (AGS) did in the Apollo
LM. BFS was specialized for abort functionality, i.e.,
reentry in the absence of a reliable set of GPCs running
PASS. And as I said above, this capability was really
(potentially) needed only during ascent or reentry.
The data buses interconnecting the GPCs and peripheral devices,
physically and electrically, were MIL-STD-1553 buses.
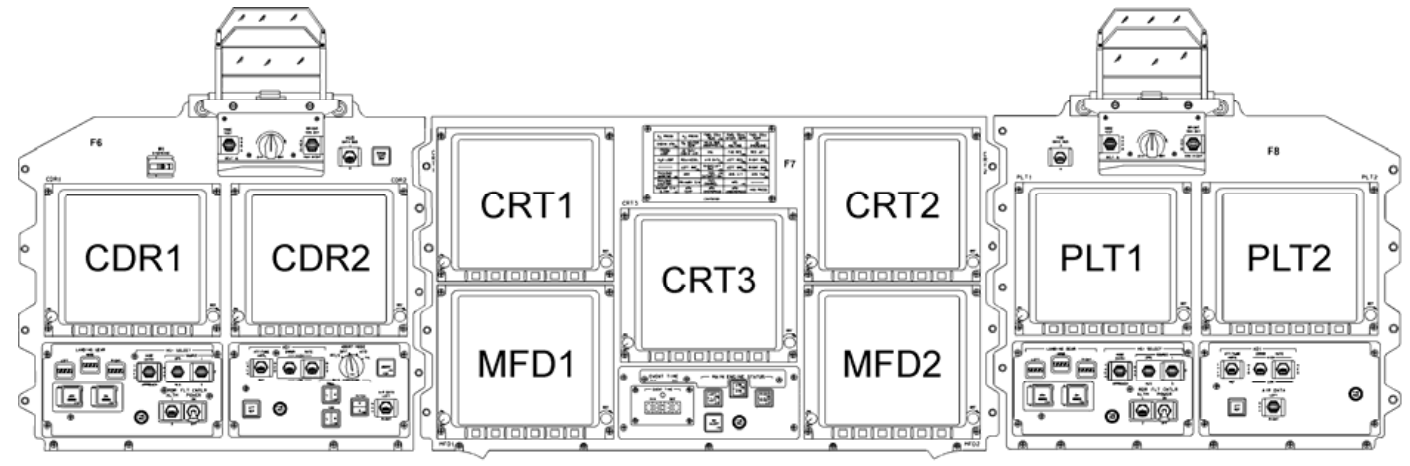
The crew-interface devices included:
- 26 line by 51 character displays, capable also of
displaying some graphics. Prior to about the year
2000, the pilots had 3 of these displays and the crew
specialist had 1; they were monochrome (green text on black
background) cathode-ray tubes (CRTs). After 2000, the
CRTs were replaced by multi-color liquid crystal displays
(LCDs), 9 for the pilots and 2 elsewhere.
Collectively, the CRTs and LCDs were referred to as Multifunction
Display Units (MDUs).
- Keyboards. The pilots had 2 of these, and the
mission specialist station had a 3rd.
The pre-2000 configuration was known collectively as the Multifunction
CRT Display System (MCDS), while the post-2000
configuration was known as the Multifunction Electronic
Display Subsystem (MEDS).
In the diagrams below, the pre-2000 configuration is shown on
the left, while the post-2000 configuration is shown on the
right. Notice that the LCD-based displays (on the right)
have 6 buttons along the bottom edges that the CRTs (on the
left) lack, as well as being taller relative to their
width. The LCDs continued to display 51×26 textual
characters, just as the CRTs had, but the text was scrunched
into the upper part of the screen, while a strip along the
bottom of the LCD could display additional stuff that the CRTs
hadn't been able to, such as menu options selectable by the
edge buttons. These differences were transparent to the
PASS / BFS flight software, because the additional stuff
displayed along the bottom was not controlled by the PASS /
BFS software. In contrast, keyboards were the same in
type and number throughout the duration of the Shuttle
program.
There's a more-inclusive diagram below (click to
enlarge) of the entire
older configuration of the
avionics system, if you feel the need for one. Personally,
I'm just including it because it's colorful, and you'll need to
dig into the actual documentation if you want real detail.
By the way, you can tell it's the older configuration (MCDS)
rather than the newer one (MEDS), because if you look in the
upper-left area, you'll see "CRT 1", "CRT 2", "CRT 3", and
(somewhat below the others) "CRT 4", rather than the 11 MFDs
you'd see in the newer configuration:
Below, on the other hand, is an extremely-informative diagram of
display-system interconnections that specifically for the newer
MEDS configuration. Don't be confused by the fact that
some of the LCDs are designated by names like "CRT
N",
because they're
not CRTs; they're just legacy names!
Like the AGC, AGS, and LVDC, which were programmed essentially
in the assembly language native to their CPU types, the Flight
Control Operating System (FCOS) was written the assembly
language of the AP-101S CPU. But once you get past those
infrastructural software components, the bulk of PASS
application code was written in a higher-level language called
HAL/S, as was the BFS.
The DPS
Overview Workbook explains the overall structure of PASS
better than I can:
"PASS software consists of two types of software:
system software and application software. System software runs
the GPC. It is responsible for tasks such as GPC–to–GPC
communication, loading software from MMUs, and timekeeping
activities. Application software is software that runs the
orbiter. This includes software that calculates orbiter
trajectories and maneuvers, monitors various orbiter systems
(such as power, communications, and life support), and
supports mission–specific payload operations. The application
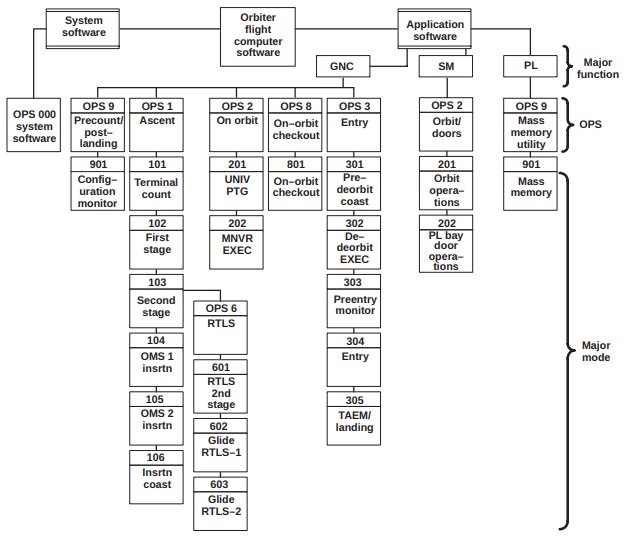
software is divided into broad functional areas called major
functions; in turn, each major function consists of
Operational Sequences (OPS), which are loaded into the GPCs
for each major phase of flight.
"Finally, each OPS has one or more Major Modes (MMs) that
address individual events or subphases of the flight."
Schematically, you can see in the diagram below how the
application software was structured, at least in one version of
the flight software. Over the decades in which the
Shuttle's flight software was in use, there were certainly
changes to this structure.
References
All documents I can find that I feel are relevant to discussion
of the Space Shuttle's onboard computer systems and their software
have been collected on our Space Shuttle Library page.
That should be your first stop in a documentation
pilgrimage! However, here are some websites that have
additional documents that you may find interesting, and which may
still contain relevant materials that I've overlooked:
PASS, BFS, and Other Shuttle Source Code
I have become aware of the survival of some late
revisions of the Shuttle's flight software, both primary
(PFS/PASS) and backup (BFS, partial only). This is
remarkable, given that a former developer of Shuttle software has
told me that:
"When NASA shut down the Space Shuttle project, they erased all
of the backup storage media — since there WAS NO REQUIREMENT for
saving source code! Most of the HAL/S compiler and related
tools (like ... other support software were not saved), but all
of the HAL/S-based flight code was preserved."
In fact, I filed a Freedom of Information Act (FOIA) request with
NASA's FOIA Office to get a copy of the flight software from NASA,
but after several months of looking around they asserted that they
didn't have a copy of it. So apparently NASA fully lived up
to the lack of a requirement for preserving it, in spite of the
assertion of my informant that the flight code had in fact been
mysteriously saved (somewhere) after all. My developer
informant also told me that the Shuttle flight-code was the
most-expensive software-development project of all time.
Good job all around, U.S. Government agencies, preserving
tax-payer investment!
But I digress.
Unfortunately, confirming that the source code for the
Shuttle's flight software still exists is not the same thing as
saying that I've convinced anybody to give me all of it.
Without being too specific, I will simply say that I presently
have significant quantities of PASS source-code files in hand,
along with some BFS files, but that I am not at liberty to show
them to you due to issues which I hope can eventually be
resolved. Indeed, I can't even necessarily tell you
yet everything I have managed to acquire. It's an unpleasant
situation that I hope and expect to improve over time.
On the other hand, here is some software source code we do
have, and which you can see right now in our source tree:
- HAL/S-FC — the HAL/S compiler, used to actually compile PASS
and BFS. More specifically, HAL/S-FC
release 32V0, written mostly in an enhanced version of the
XPL high-level language, with bits in BAL (IBM 360 Basic
Assembly Language) and in AP-101S assembly language as
well. More on
this below.
- XCOM — the source code for the original "standard" XPL
compiler. Alas, it is guaranteed not to compile
HAL/S-FC, since HAL/S-FC was written in an enhanced version of
the XPL language, which I call "XPL/I", but which Intermetrics
unfortunately continued to call just "XPL". I will persist
in calling it XPL/I, however, because there are reasons the
distinction is important. Intermetrics's compiler for
XPL/I, to the best of my knowledge, has not survived the end of
the Shuttle program. Nevertheless, there are reasons why
the source code for the standard compiler remains useful, and
perhaps those reasons will become clear below. Although it
is not the contemporary software used during Shuttle
development, I have
myself written an XPL/I compiler called XCOM-I which
is capable of compiling HAL/S-FC.
Is this the Original Source Code?
To the extent that we can present the contemporary source
code for Shuttle-related software here, or to work with it using
the tools provided on this site, some alterations from the
original source code files have been needed. We hope that
these changes are not substantive, but a difference is a
difference, and you're entitled to know about it if you're
interested.
For one thing, Virtual AGC header blocks, consisting of program
comments, are added at the top every contemporary file we receive,
so that you can understand the provenance of the files as much as
possible. These comments are crafted in a way that lets you
distinguish such "modern" comments from the original contents of
the files.
Flight software files, when they become available, are
expected to be "anonymized" or "depersonalized", so as to remove
all personally-identifying information related to the original
development teams; thus, whenever the name or initials of a
programmer are discovered in the program comments of Shuttle
flight software, we have replaced them by a unique but impersonal
numerical codes. This is at the behest of some holders of
the original source materials, as a condition for obtaining the
software. Whether this is a temporary or permanent
condition, I cannot say.
Most significant, I expect, is the fact that the character
encoding of all contemporary Shuttle source code has been
completely changed. This necessity arises directly or
indirectly from the fact, unfortunate from our point of view, that
the contemporary character-encoding system used was an IBM system
called EBCDIC (Extended Binary Coded Decimal Interchange Code),
while modern source code (as far as I know) is universally encoded
using 7-bit ASCII (American Standard Code for Information
Interchange) or extension of it such as UTF-8. But EBCDIC
and ASCII are essentially 100% incompatible, with only rare,
accidental overlaps. The recoding of the source-code files
from EBCDIC to ASCII has been done before we ever received any of
the files, and was performed by unknown people, at an unknown
time, using an unknown process. Nor was it always perfectly
done, and has required occasional corrections by us.
Moreover, the EBCDIC vs ASCII issue isn't quite as simple as the
preceding paragraph suggests, because not all of the EBCDIC
characters used originally actually have ASCII equivalents.
There are special considerations regarding how you need to work
with HAL/S source code in light of those characters not supported
by ASCII.
Here are the general rules:
- HAL/S source code should be encoded using 7-bit ASCII
characters.
- Two characters originally used in HAL/S source code and in the
original documentation, namely the logical-not character "¬" and
the U.S. cent character "¢", are not present in 7-bit
ASCII. So instead, we use the ASCII characters "~" and
"`", respectively, in place of them. For example,
every time you might have seen something like "x ¬=
y" in the original HAL/S source code or documentation,
we'd expect "x ~= y" instead!
- A compiler directive of the form "D VERSION v"
was sometimes used in original HAL/S source code or
template-library files. Here, "v" is a
numerical version code in the range of 1 through 255, represented
as a single EBCDIC character. To reiterate, a single
character position in this compiler-directive string must
represent up to a 3-digit version number. The way they did
this originally was simply to pretend that the version code was
the numeric byte encoding for a character, and to insert that
single-byte numeric code into the string. For example, if
the version was 1, then instead of using the character "1" in
the compiler directive, the numerical byte 1 was inserted.
This would have been legal in EBCDIC, even though rather
inconvenient since in most cases the character would have been
unprintable. In ASCII or UTF-8, the problem goes beyond
that, and such a single-character usage doesn't even represent a
valid ASCII or UTF-8 character half of the time. So we
cannot continue to follow this odd practice. Our change is
to instead require this compiler directive to have the form "D
VERSION xx", where xx is a
2-character string of hexadecimal digits.
Aside: With that said, if your
operating system supports UTF-8 character coding rather than
simple 7-bit ASCII, you can continue to use "¬" and "¢" in
HAL/S source code. The compiler transparently converts
them to "~" and "`" during the compilation, and then converts
them back to "¬" and "¢" in printouts or in messages it
displays. In particular, this does work fine in Mac OS
and Linux, though there may be special considerations trying
to do this in Microsoft Windows, discussed later. In
some of the source code we receive, ¬ has instead already been
replaced by "^". Thus any software we provide also
silently converts "^" to "~".
A longer explanation is that for some decades now, the most-common
character encoding in the U.S. has been 7-bit ASCII, 128 characters
in all, sometimes called "plain vanilla" ASCII or just
"ASCII". But since the Space Shuttle's flight software was
originally developed on IBM mainframe systems like System/360,
rather than using ASCII it used an 8-bit character-encoding scheme
called EBCDIC. It's pretty difficult to find any two EBCDIC
tables that agree on all 256 characters, because various IBM systems
seemed to have used slightly-different versions of EBCDIC. But
here are ASCII and EBCDIC tables I pulled from Wikipedia that give
the basic idea:
| ASCII (1977/1986) |
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
| 0x |
NUL |
SOH
|
STX
|
ETX |
EOT |
ENQ |
ACK
|
BEL |
BS |
HT
|
LF
|
VT
|
FF
|
CR |
SO
|
SI
|
| 1x |
DLE
|
DC1
|
DC2
|
DC3
|
DC4
|
NAK
|
SYN |
ETB
|
CAN |
EM
|
SUB |
ESC |
FS
|
GS
|
RS
|
US
|
| 2x |
SP
|
! |
" |
# |
$ |
% |
& |
' |
( |
) |
* |
+ |
, |
- |
. |
/ |
| 3x |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
: |
; |
< |
= |
> |
? |
| 4x |
@ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
J |
K |
L |
M |
N |
O |
| 5x |
P |
Q |
R |
S |
T |
U |
V |
W |
X |
Y |
Z |
[ |
\
|
] |
^ |
_
|
| 6x |
` |
a
|
b
|
c
|
d
|
e
|
f
|
g
|
h
|
i
|
j
|
k
|
l
|
m
|
n
|
o
|
| 7x |
p
|
q
|
r
|
s
|
t
|
u
|
v
|
w
|
x
|
y
|
z
|
{ |
|
|
} |
~ |
DEL |
| EBCDIC |
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
| 0x |
NUL |
SOH
|
STX
|
ETX |
SEL
|
HT |
RNL
|
DEL |
GE
|
SPS
|
RPT
|
VT |
FF |
CR
|
SO |
SI
|
| 1x |
DLE
|
DC1
|
DC2
|
DC3
|
RES/
ENP |
NL
|
BS
|
POC
|
CAN |
EM
|
UBS
|
CU1
|
IFS |
IGS |
IRS |
IUS/
ITB
|
| 2x |
DS
|
SOS
|
FS
|
WUS
|
BYP/
INP |
LF |
ETB |
ESC |
SA |
SFE
|
SM/
SW |
CSP
|
MFA
|
ENQ |
ACK |
BEL |
| 3x |
|
|
SYN |
IR
|
PP
|
TRN
|
NBS
|
EOT |
SBS
|
IT
|
RFF
|
CU3
|
DC4
|
NAK |
|
SUB
|
| 4x |
SP
|
|
|
|
|
|
|
|
|
|
¢ |
. |
< |
( |
+ |
|
|
| 5x |
& |
|
|
|
|
|
|
|
|
|
! |
$ |
* |
) |
; |
¬ |
| 6x |
- |
/ |
|
|
|
|
|
|
|
|
¦ |
, |
% |
_ |
> |
? |
| 7x |
|
|
|
|
|
|
|
|
|
` |
:
|
#
|
@ |
' |
= |
" |
| 8x |
|
a |
b |
c |
d |
e |
f |
g |
h |
i |
|
|
|
|
|
± |
| 9x |
|
j |
k |
l |
m |
n |
o |
p |
q |
r |
|
|
|
|
|
|
| Ax |
|
|
s |
t |
u |
v |
w |
x |
y |
z |
|
|
|
|
|
|
| Bx |
^ |
|
|
|
|
|
|
|
|
|
[ |
] |
|
|
|
|
| Cx |
{ |
A |
B |
C |
D |
E |
F |
G |
H |
I |
|
|
|
|
|
|
| Dx |
} |
J |
K |
L |
M |
N |
O |
P |
Q |
R |
|
|
|
|
|
|
| Ex |
\ |
|
S |
T |
U |
V |
W |
X |
Y |
Z |
|
|
|
|
|
|
| Fx |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
|
|
|
|
EO |
In UTF-8, the funky characters "¬" and "¢" are represented by the 2-byte
sequences 0xC2 0xAC and 0xC2 0xA2, respectively, and they don't
appear at all among the 128 characters of ASCII, but do appear among
the 256 characters of some versions of EBCDIC.
HAL/S
HAL/S is a high-level programming language in which the PASS and
BFS application software was written. Whereas
infrastructural software (like operating systems and run-time
libraries) was written in whatever assembly-languages were native
to the particular CPUs running that code.
HAL/S is a compiled language, and the HAL/S flight-software
source code was compiled down to a machine-code executable before
it could be run. Compilers existed for it that could be used
on several different types of computers. Some of the
compilers produced code that could be run on an IBM System/360
mainframe; others could produce executable code for the Shuttle's
IBM AP-101S onboard computers; others produced executable code for
other computers.
I'm sure you can't help but notice that "HAL" was the name of the
computer in the movie 2001: A Space Odyssey, which came
out in 1968, not too many years before the HAL/S language was
invented. In the movie, H.A.L. stood for "Heuristic
Algorithmic Logic", and many people have observed that H.A.L. was
just one letter away from I.B.M. (I.e., "H" is one letter
before "I" in the alphabet, "A" is one letter before "B", and "L"
is one letter before "M".) The writer of the movie, Arthur
C. Clarke, maintained that that was simply a coincidence.
Where the "HAL" in HAL/S comes from has likewise been explained in
several ways, none of them relating to 2001: A Space Odyssey.
The HAL/S language was invented (and the flight software was
written) by a company called Intermetrics, many of whose employees
were refugees from the same Draper Laboratories (MIT
Instrumentation Laboratory) at which the Apollo flight software
had been written. One of those refugees was Ed Copps, one of
Intermetrics's founders, who is said to have named the HAL/S
language in honor of Hal Laning, perhaps the most-prominent among
the designers of the Apollo Guidance Computer's hardware.
Others offer the explanation that HAL/S is an acronym for
"High-order Assembly Language / Shuttle". Still
others state that "the acronym 'HAL' was never formally
defined". I have even seen one report (NASA-CR-141758) that
refers to it as "Houston Aerospace Language". Well, who
knows? It's fun to make up your own mind about which
constellation of facts matches your own preferences.
Probably not Houston Aerospace Language! But all I
can really say for sure is that there's nothing "heuristic" about
HAL/S, even if 2001 may secretly have been somewhere in
the back of somebody's mind.
But I digress. As I was saying, the HAL/S software for some
revisions of the Shuttle's PASS and BFS still survives, which is
much better than the alternative of it not existing
anywhere. At present, I am enjoined to keep that which I do
have private.
Assuming that we can eventually get access to it, working with
the application software's source code requires knowledge of the
HAL/S language. Fortunately, we have a fair amount of
documentation of that:
- The recommended starting point is "Programming
in HAL/S" by Michael Ryer, which was intended as an
introduction to programming in HAL/S and is organized as a
tutorial.
- A great supplement to Ryer is the course material for "Basic
HAL/S Programming" by Craig Schulenberg. Additional
material associated with that course can be found on our Shuttle
library page.
- Ryer's book points out that it is not a definitive exposition
of the language, and recommends proceeding afterward to the "HAL/S
Language Specification", which contains a much-more-formal
specification of the language syntax, both in the form of graphs
of the syntax and in Backus-Naur form (BNF).
- Or to the "HAL/S
Programmer's Guide".
- And then there's the "HAL/S-FC
User's Guide" explains how to compile and execute a HAL/S
program. That explanation is, of course, completely
irrelevant to our present situation, but you may find that the
document answers some questions left unanswered by the preceding
documents. (You many notice as well that our library
contains a "HAL/S-360 User's Guide"; that's simply a predecessor
of the "HAL/S-FC User's Guide". The former assumes that
the computer on which the compiler ran was an IBM-360, while the
latter assumed it was some arbitrary "mainframe" to which the
compiler had been ported.)
We actually have quite a few revisions of some of these documents
in our library, spanning the mid-1970's to the mid-2000's, though
I've only chosen to link the latest versions of those documents
above, even though from time to time the latest revision isn't
always the most complete one.
Here's a brief sample of HAL/S code from "Programming in HAL/S",
just to give you its flavor:
FACTORIAL:
PROGRAM;
DECLARE INTEGER,
RESULT, N_MAX, I;
READ(5) N_MAX;
RESULT = 1;
DO FOR I = 2 TO N_MAX BY 1;
RESULT = I
RESULT;
END;
WRITE(6) 'FACTORIAL=', RESULT;
CLOSE FACTORIAL;
What this program does is to read a number (N_MAX),
compute its mathematical factorial, then output the result.
While I won't dissect this short program in detail, I can make a
couple of observations. For one, the language is strongly
typed, meaning that every variable has a type that's
declared at compile time, and that storage for it is fixed and
unalterable at run-time. Nor is there any dynamic memory
allocation (as well as no stack and no recursion), so RAM usage is
completely known at compile time. HAL/S programs never
unexpectedly abort because memory has filled up. The other
observation is that the READ(5) and WRITE(6)
statements are very familiar to FORTRAN users ... or at least to
FORTRAN users of (say we say?) a certain vintage. In
FORTRAN-speak, the 5 and 6 are "logical unit numbers" (LUN) whose
specific interpretation as keyboard and printer (or keyboard and
display, or even as files) are assigned externally by the Job
Control Language (JCL) used to run the job. This reflects
the fact that the first HAL compilers targeted IBM 360 computers
rather than the Shuttle's computers. In the Shuttle
software, these READ and WRITE constructs, I think,
wouldn't have been used, and keyboard input or display output
would instead have been handled by calls to the run-time library.
HAL/S actually has many novel features not visible in the FACTORIAL
example, such as those devoted to real-time response and scheduling
of execution. Again, I won't get into most of those
here.
With that said, perhaps the most-novel feature is a superficial one,
namely the ability to express mathematical formulae in a multi-line
format that the language's designers felt was more self-documenting
than the usual single-line manner of expressing mathematical
formulae in programming languages. One comment made several
times in the documentation is that it's worthwhile for the
programmer to spend more time than one is usually inclined to do to
make the source code easy to read ... because more time will
eventually be spend reading the code than was spent writing
it. I.e., the time lost in creating readable code is more than
made up for by the savings in maintaining the code later. This
is sound engineering doctrine, according to the software-design
literature of the time ... but very far from today's actual
practice and attitudes (2022), in which the initial design schedule
is everything, and downstream maintenance is an afterthought
performed by somebody management doesn't have to budget time or
money for today. That turns out not to be a problem
for HAL/S, though, because while you could input source-code
in this multi-line format, you weren't required to, and usually did
not do so. But, the compiler always used the multi-line format
in its output listings, so you got the benefit of reading it without
the hassle of writing it.
So were the HAL/S designers on the right side or the wrong side of
history in this respect? (That's an exercise for the reader.)
What the multi-line format mainly does is to allow a more-natural
representations of superscripts and subscripts. Here's a HAL/S
sample that illustrates the multi-line pseudo-mathematical format:
C Compute corners of a parallelogram.
CORNERS: PROGRAM;
DECLARE SCALAR,
LONG, SHORT, ALPHA;
DECLARE VECTOR(2),
AB, BC, CD, DA;
READ(5) LONG, SHORT, ALPHA;
E -
M AB = 0;
E -
M BC = VECTOR (LONG, 0);
S
2
E -
M DA = VECTOR (SHORT COS(ALPHA), SHORT
SIN(ALPHA));
S
2
E -
- -
M CD = BC + DA;
E
- - - -
M WRITE(6) AB, BC, CD, DA;
CLOSE CORNERS;
What this example program does is to allow input of parameters
describing a parallelogram — namely, the lengths of a "short" side
and a "long" side (which is assumed to be along the x-axis),
and the angle between them in radians — and then to output the (x,y)
coordinates of the four corners. The code also illustrates
another of HAL/S's novel features, in that it can do arithmetic not
just on scalar variables like integers or floats, but also do vector
arithmetic or even matrix arithmetic. For example, vector/matrix
addition or subtraction, vector dot products or cross products,
matrix multiplication or inversion, etc. Functions like COS
or SIN or VECTOR2 (which forms a
2-vector from two scalar inputs) were available in the run-time
library or as compile-time arithmetic when appropriate.
It's important to realize that the lines with the leading characters
E, M, and S in the example above are
active code rather than merely program comments. In HAL/S,
column 1 has a special purpose. Normally that column is
blank. True, if a C appears there, it actually is
a full-line comment, just like in Fortran. If a D
appears there, then the line is a compiler directive. But for
a multi-line mathematical form, M in column 1 indicates
the formula's "main" line, whereas E indicates an
"exponent" line and S indicates a "subscript" line.
You can see that several places above. When this multi-line
math format is discussed, it's generally described as a "3-line"
format. But in fact, there was no limit to the number of E
or S lines associated with a given M line.
For example, here's some valid code:
E
DEX$J
E
I
I
M
COEF
ALPHA
S
L
S
M**2
But you'll notice that if you have a subscript in an E
line or an exponent in an S line (as in DEX$J or
M**2 above), you just have to live with those
little bits remaining in single-line notation. (In fact,
there's not even any real need to put an M in
column 1 for a main line, since the M meant exactly the
same thing to the original compilers as a blank in column 1.
I'm told — thank heaven! — that nobody ever actually did omit the M's.)
In the multi-line math format, if a variable (like AB) has
a '-' above it, that means that AB is really a
vector. Actually, a 2-vector, in the example code above.
That's reflected in the declaration "DECLARE VECTOR(2), AB, ...".
And '-' isn't the only datatype-related character that can
appear in the E line above a variable in the M
line:
- '-' for vectors.
- '*' for matrices.
- ',' for strings.
- '.' for booleans.
- '+' for structures.
Collectively, these were referred to as "overpunches".
My impression is that creating source code in this multi-line format
is a pain in the neck, since aligning the columns cards isn't that
easy. But as I said, HAL/S doesn't actually require
the use of this E/M/S multi-line format for (input of)
mathematical formulas. A single-line format is perfectly valid
as well, and for the CORNERS program would look like this:
CORNERS: PROGRAM;
DECLARE SCALAR,
LONG, SHORT, ALPHA;
DECLARE VECTOR(2),
AB, BC, CD, DA;
READ(5) LONG, SHORT, ALPHA;
AB = 0;
BC = VECTOR$2(LONG, 0);
DA = VECTOR$2(SHORT COS(ALPHA), SHORT
SIN(ALPHA));
CD = BC + DA;
WRITE(6) AB, BC, CD, DA;
CLOSE CORNERS;
In the single-line format, The beginning of a subscript is indicated
by the '$' character.
One thing you may take away from this is that the overpunches ('-',
'*', '+', ...) which appear on the E
lines to indicate vector vs scalar variables weren't really needed,
since they don't show up in the single-line notation at all; in
fact, they're just eye-candy that's nice for readability, and are
actually discarded by the compiler. Whereas the subscript '2'
which appears on the S line is in fact quite necessary,
since VECTOR() isn't the same thing as VECTOR2(),
which isn't the same thing as VECTOR3().
There was also a kind of decoration which the compiler added to
invocations of "macros", which were string substitutions (like the #define
in C or C++) made on the source code before any actual compilation
was performed. Such invocations were underlined in printouts.
My guess is that almost all source code was written in the
single-line format ... and indeed, I've been told by one of the
original developers that this is so. However, realize that yet
another novelty of HAL/S is that the original compiler allowed the
programmer no control whatsoever over the format of the
output compiler listings. Those were always
pretty-printed according to the standards decided upon by the
designers of the compiler. (Well, I think that maybe
pretty-printing could be turned off, but that doesn't mean the
person writing the code controlled the format.)
The same is true of any other formatting decisions. I
mentioned above that column 1 of the source code has a special
purpose, and thus it matters what characters appear in column 1 vs
other columns. But for all lines which have blanks in column
1, the input source code is completely free-form: Multiple
statements can appear on a single line. Individual statements
can be broken across multiple lines. Empty lines and
whitespaces within lines are ignored, except where at least one
space is needed between two adjacent identifiers. (And except
in comments or literal quoted strings.)
The latter point is interesting in connection with the operation of
multiplication. While HAL/S has the usual operators for a lot
of mathematical or logical operations, such as "-" for
subtraction, "/" for division, "**" for
exponentiation, and so on, it has no operator for multiplication.
Multiplication is indicated simply by placing variable names,
constant names, or literal numbers adjacent to each other (separated
by whitespace). For example,
DECLARE SCALAR, X, Y, Z;
DECLARE INTEGER, I, J, K;
X = Y Z ;
I = 2 J K ;
By the way, SCALAR is what HAL/S calls its
floating-point type; thus SCALAR contrasts with INTEGER
or BOOLEAN datatypes, but not with VECTOR or MATRIX.
In fact, all VECTOR and MATRIX objects consist
entirely of SCALAR values. You can't have (say) a
VECTOR of INTEGER values. On the other
hand, there is an ARRAY type, of arbitrary
dimensionality, which can hold values of any datatype you like,
including VECTOR and MATRIX. And as it
turns out, there actually is an operator '*', but it is
the vector cross-product operation, not a multiplication of two
numbers. Similarly, the '.' operator is a vector
dot product.
Software Versioning
As I've described above, any given shuttle had a number of
computers, running a lot of different software components — more
than just the GPCs running PASS/BFS we're discussing here.
Each of these software components had their own unique
versioning. I couldn't begin to tell you what those all are;
I don't even have a list of all the different computers or their
software components, let alone details about their versions.
However, in all but the very earliest missions, the collection
of all of the software components at their various revision levels
was itself identified by what's called the Operational
Increment (OI). You thus see various Shuttle documents
specifying "OI-24" or "OI-33", and what this means is that those
documents are specialized to those particular overall software
versions. The versioning of individual software components
of the overall software version was apparently by Version
Increments (VI), such as "VI 1.23".
At this point, I have no authoritative single document that links
software versions to specific Shuttle missions. For what
information I do have, I'd refer you to the Space
Shuttle Missions Summary. In the following tabulation,
sorted by software version, notice that a higher STS mission
number sometimes has a lower software version number, presumably
partially because the mission numbering doesn't perfectly agree
with the chronological order in which the missions were
flown. For that matter, notice confusing duplicate numbers,
like the entire range STS-26 through STS-33 (skipping STS-29); not
my fault, blame NASA!
Mission
|
Software Version
|
STS-1
|
R16/T9
|
STS-2, STS-3, STS-4
|
R18/T11
|
STS-5, STS-6, STS-7, STS-8
|
R19/T12
|
STS-9 (STS 41-A), STS-11
(STS 41-B), STS 41-C (STS-13)
|
OI-2
|
STS 41-DR (STS-14), STS
41-G (STS-17), STS 51-A (STS-19),
STS 51-C (STS-20), STS 51-E (STS-22), STS 51-B (STS-24) |
OI-4
|
STS 51-D (STS-23), STS-51-E
(STS-22)
|
OI-5
|
STS 51-F (STS-26)
|
OI5-24
|
STS 51-G (STS-25)
|
OI-6
|
STS 51-I (STS-27)
|
OI6-27
|
STS 51-J (STS-28)
|
OI6-28
|
STS 61-A (STS-30)
|
OI6-29
|
STS 61-B (STS-31)
|
OI6-30
|
STS 51-L (STS-33)
|
OI17-26
|
STS 61-C (STS-32)
|
OI17-32
|
STS-26 (STS-26R), STS-27
(STS-27R), STS-28 (STS-28R),
STS-29 (STS-29R), STS-30 (STS-30R), STS-33 (STS-33R)
|
OI-8B
|
STS-31 (STS-31R), STS-32
(STS-32R), STS-34 (STS-34R),
STS-36 (STS-36R)
|
OI-8C
|
STS-35 (STS 61-E), STS-38,
STS-40, STS-41
|
OI-8D
|
STS-37, STS-39
|
OI-8F
|
STS-42, STS-43, STS-44,
STS-45, STS-48
|
OI-20
|
STS-46, STS-47, STS-49,
STS-50, STS-52, STS-53, STS-54,
STS-55, STS-56
|
OI-21
|
STS-51, STS-57, STS-58,
STS-59, STS-60, STS-61, STS-62,
STS-68
|
OI-22
|
STS-63, STS-64, STS-65,
STS-66, STS-67
|
OI-23
|
STS-69, STS-70, STS-71,
STS-72, STS-73, STS-74, STS-75,
STS-76, STS-77, STS-78
|
OI-24
|
STS-79, STS-80, STS-81,
STS-82, STS-83, STS-84,
STS-94 (STS-83R)
|
OI-25
|
STS-85, STS-86, STS-87,
STS-89
|
OI-26
|
STS-88 (ISS-2A), STS-90,
STS-91, STS-93, STS-95, STS-103
|
OI-26B
|
STS-92 (ISS 3A), STS-96
(ISS-2A.1), STS-97 (ISS 4A), STS-99,
STS-101 (ISS 2A.2a), STS-106 (ISS 2A.2b)
|
OI-27
|
STS-98 (ISS 5A), STS-100
(ISS 6A), STS-102 (ISS 5A.1),
STS-104 (ISS 7A), STS-105 (ISS 7A.1), STS-108 (ISS UF-1),
STS-109
|
OI-28
|
STS-107, STS-110 (ISS 8A),
STS-111 (ISS UF-2), STS-112 (ISS 9A),
STS-113 (ISS 11A)
|
OI-29
|
STS-114 (LF-1), STS-115
(ISS 12A), STS-116 (ISS 12A.1),
STS-117 (ISS 13A), STS-118 (ISS 13A.1), STS-121 (ULF1.1)
|
OI-30
|
STS-120 (ISS 10A), STS-122
(ISS 1E), STS-123 (ISS 1JA),
STS-124 (ISS 1J), STS-125
|
OI-32
|
STS-119 (ISS-15A), STS-126
(ISS-ULF2), STS-127 (ISS-2JA)
|
OI-33
|
STS-128 (ISS 17A), STS-129
(ULF3), STS-130 (ISS 20A),
STS-131 (ISS 19A), STS-132 (ULF4), STS-133 (ULF5),
STS-134 (ULF6), STS-135 (ULF7)
|
OI-34
|
For example, the presentation for the STS-121
Flight Readiness Review (FRR) tells us that the software
version was OI-30, in agreement with the table above, while just
the Integrated Display Processor (IDP) software component was
version VI 4.01 and the Multifunction Display Unit Function (MDUF)
was version VI 5.00.
Multi-Function Display Formatting and
Versioning
As was mentioned earlier in the Introduction, the principal method by
which the General Purpose Computers (GPC) running the primary
flight software (PASS) and backup flight software (BFS) interact
with the crew includes keyboards and display screens. What's
unusual about the display screens is that what appears on them is
only partially controlled by the PASS or BFS
software. Instead, there was another processor sitting
between each of the displays and the GPCs, and it was this extra
processor that directly controlled what was displayed and how the
display was formatted. (For that matter, the keyboards also
were attached to one of these extra processors rather than to the
GPCs, so whatever keystrokes were seen by the PASS / BFS software
had already been pre-digested by these extra processors.)
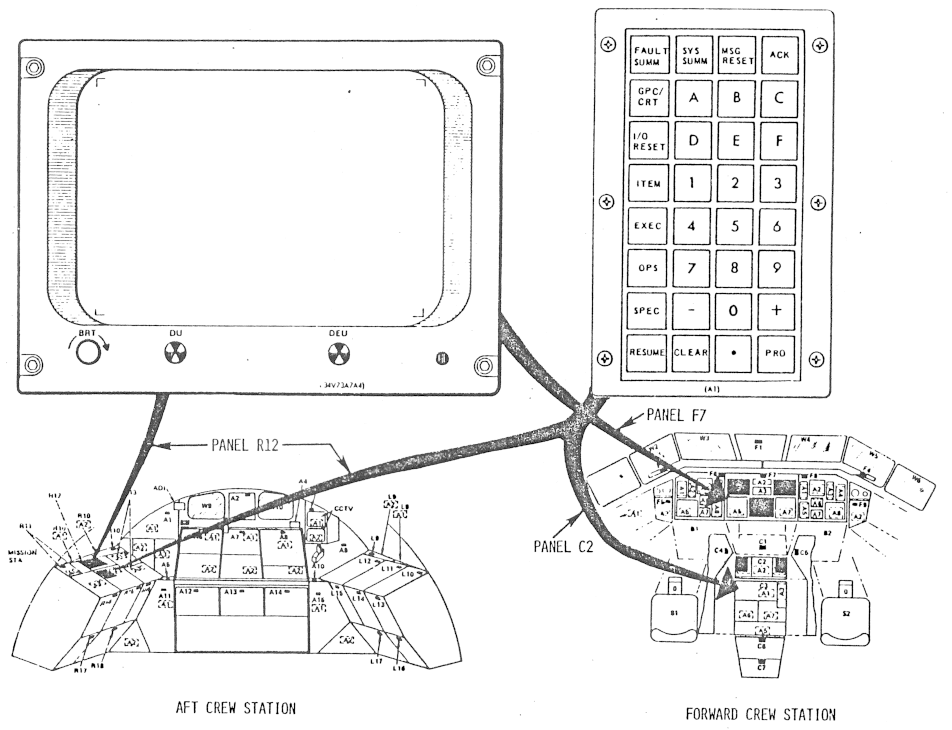
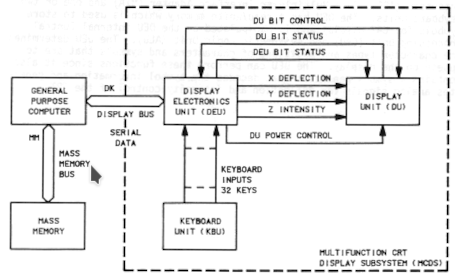 In the case of the older, pre-2000
cockpit configuration (MCDS, 4 CRTs), this extra processor was
known as the Display Electronics Unit (DEU), and it
consisted of an IBM SP-0 CPU with 8K×16 bits of RAM. In the
case of the newer, post-2000 cockpit configuration (MEDS, 11
LCDs), the extra processor was known as the Integrated Display
Processor (IDP), an Intel 368DX microprocessor. The basic
schema is seen in the diagram to the right. While the
diagram is specific to the older (MCDS) configuration, the newer
(MEDS) configuration is conceptually quite similar. In the
case of the MEDS configuration, the software for the IDP that was
specifically tasked with formatting the display was called the Display
Application Software (DAS). But these kinds of details
are of little interest to us in the absence of the DAS or other
software that actually ran on the DEU/IDPs. So the only use
of these factoids I'll make in the context of the present
discussion is to refer from now on to what I've been calling the
"extra processor" instead as the "DEU/IDP".
In the case of the older, pre-2000
cockpit configuration (MCDS, 4 CRTs), this extra processor was
known as the Display Electronics Unit (DEU), and it
consisted of an IBM SP-0 CPU with 8K×16 bits of RAM. In the
case of the newer, post-2000 cockpit configuration (MEDS, 11
LCDs), the extra processor was known as the Integrated Display
Processor (IDP), an Intel 368DX microprocessor. The basic
schema is seen in the diagram to the right. While the
diagram is specific to the older (MCDS) configuration, the newer
(MEDS) configuration is conceptually quite similar. In the
case of the MEDS configuration, the software for the IDP that was
specifically tasked with formatting the display was called the Display
Application Software (DAS). But these kinds of details
are of little interest to us in the absence of the DAS or other
software that actually ran on the DEU/IDPs. So the only use
of these factoids I'll make in the context of the present
discussion is to refer from now on to what I've been calling the
"extra processor" instead as the "DEU/IDP".
What is of importance to us, however, is that in addition
to inputs from the GPCs via the MIL-STD-1553 databuses, the
DEU/IDP's RAM was used to store a set of templates that controlled
the formatting of the display screen. These templates were
loaded from mass memory into RAM at power-up. In other
words, the screen templates are independent of the PASS /
BFS source code.
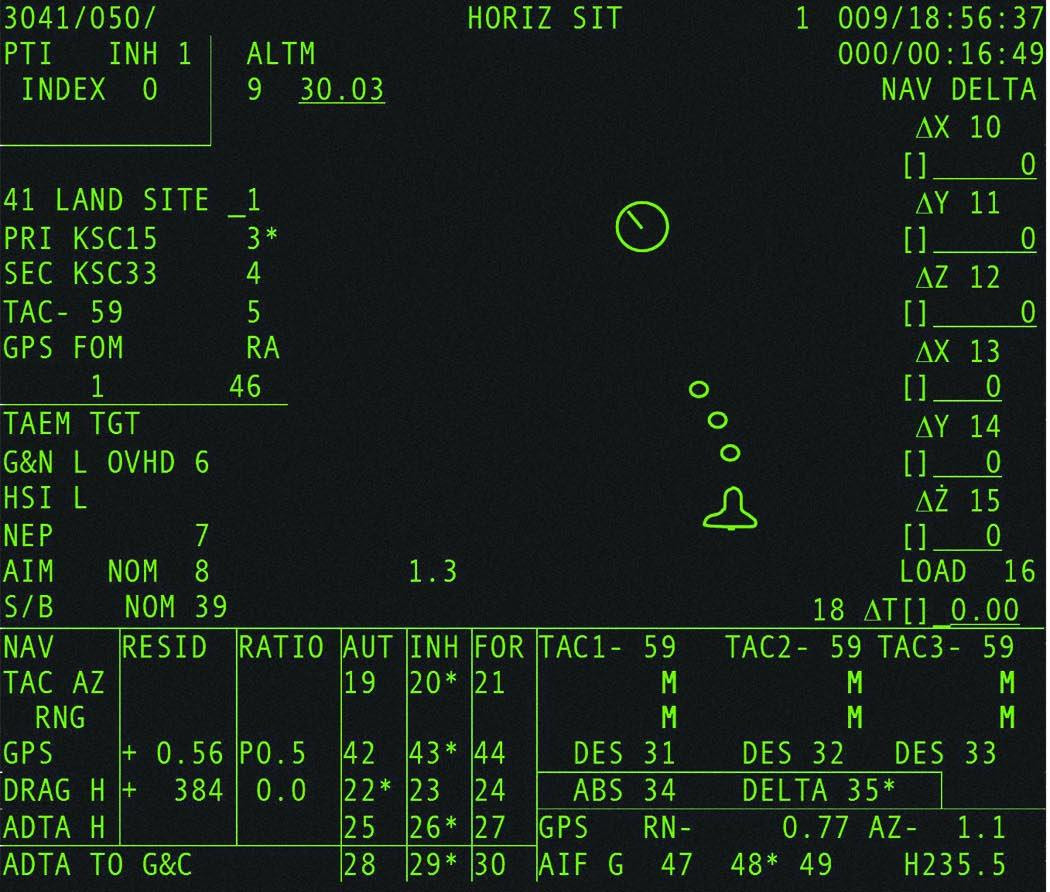
For illustrative purposes, there's an example below of the template
for screen "GNC SYS SUMM 1" for mission STS-96. It comes in
two varieties, one for the primary flight software, and one for the
backup flight software:
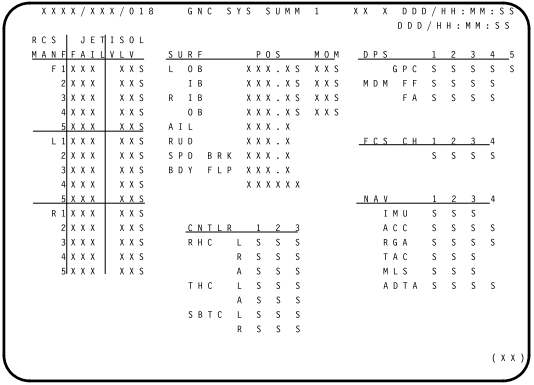
PASS GNC SYS SUMM 1 screen, STS-96
|

BFS GNC SYS SUMM 1 screen, STS-96
|
As you can probably deduce from these images, some of the areas
are supposed to be updated with data from the GPC (or elsewhere in
the spacecraft), such as the HH, MM, and SS in the upper-right
corner or the X's and S's that are all over the place. Other
markings, like the "SURF", "POS", "MOM", and "DPS" are simply
features of the template, and don't change at the whim of the GPC
or more specifically, of PASS or BFS.
The screen templates don't quite fall under the
Operational Increment (OI) top-level software-versioning scheme
we've already discussed. They do, but they are also
controlled by Program Change Notices (PCN). The
examples above are for STS-96 which flew software version OI-27,
but that doesn't mean that all missions using OI-27 necessarily
had identical screen templates. In a practical sense, what
this means is that to know the screen templates and consequent
display-screen formats for any given Shuttle mission, we must have
not merely the screen templates for that generic OI, but also the
differences to those templates that were made due to specific PCNs
... and of course, actually have the associated documentation so
that we can consult it.
Several documents provide screen templates that can be related to
one or more missions or software versions. The
most-available seems to be JSC-48017, the "Data Processing
System Dictionary". We have several revisions of
JSC-48017 in our Shuttle Library, and in principle, if we
could collect all of the different revisions, then we'd
have all of the screen templates for all of the missions. The
GNC SYS SUMM 1 sample templates above came from one such DPS
Dictionary. There are also reference-card-like
summaries that are very helpful, such as this
one for OI-34.
On the other hand, the Functional Subsystem Software
Requirements (FSSR) documents also contain these
templates, and seem a lot more authoritative, as well as providing
a lot more information. In fact, the FSSR goes so far as to give
screen coordinates for each field, and to explain how every datum
received by the DEU/IDP via the databus relates specifically to
each X and S on the display screen! Unfortunately, the FSSRs
are also a lot more numerous and a lot harder to find than DPS
Dictionaries are, so the dream of obtaining a complete set of them
seems more whimsical than obtaining a complete set of DPS
Dictionaries. Nevertheless, on balance, it seems as though
the FSSRs should be regarded as the controlling documents for the
screen templates. We just need to collect all of them, or
failing that, fall back on DPS Dictionaries when available.
For example, here are the same GNC SYS SUMM 1 templates, but for
software version OI-34 (say, mission STS-128), taken from the
FSSR. They're different than the ones shown above for
STS-96, though only barely so. Personally, I see only 4
differences, some sensible, some nonsensical, and some (I suspect)
misprints; perhaps you can find more. Incidentally, STS-96
had the MCDS (pre-2000) cockpit configuration, while STS-128 had
the MEDS (post-2000) cockpit configuration, so perhaps that has
something to do with the differences.

PASS GNC SYS SUMM 1 screen, STS-128
|

BFS GNC SYS SUMM 1 screen, STS-128
|
Computer-to-Peripheral Interface
Keyboard data was supplied to the General Purpose Computers
(GPC), and hence to the PASS/BFS software, by means of messages on
the MIL-STD-1553 databuses interconnecting the GPCs and
DEU/IDPs. Similarly, data was output by the GPCs for display
by passing messages on the databuses as well. Technical
details about this messaging can be found in the Data
Processing System Brief. I won't bother to summarize
that information here, since the document's presentation is at
least as readable as anything I might write up to supplement
it. While our only available revision of this document so
far is for the MCDS, recall that the change from the MCDS to MEDS
cockpit configurations was done in a way that was transparent to
the existing software. That implies, I hope, that the
messaging format would have been the same in either configuration.
TBD
HAL/S and AP-101S Assembly-Language
Processing
To resurrect Space Shuttle flight software requires development
tools for the HAL/S language that can be run on modern (Linux, Mac
OS, Windows) computers. A minimum subset of tools would seem
to be:
- A HAL/S compiler. Known as HALSFC, this is
available and is
covered on its own dedicated page, though it is not 100%
bug-free yet.
- An IBM AP-101S/AP-101B assembler. Known as ASM101S,
this is a work in
progress.
- An IBM AP-101S linker. Tentatively designated HALLINK101S,
this is not actually anything on which work is being done, and
so far it has no place as such on the roadmap. However,
there is a
page covering my preliminary thoughts on the subject,
especially details of the (reverse-engineered) format of AP-101
object files.
- An IBM AP-101S emulator. Known as ap101s, this
is a work in progress, but as the effort is external to the
Virtual AGC Project per se, I have few worthwhile
details to share other than that it is somewhat based on the similar
System/360 emulator, sim360, that I have described
elsewhere. But I have no up-to-date status or other
information concerning it.
Besides these things, there is also HAL/S interpreter, which
implements only a subset of full HAL/S functionality. It can
be used interactively on Linux/Mac/Windows, accepting HAL/S
statements from the keyboard and outputting results to the
display. It may be a useful tool for somebody learning to
program in HAL/S. It is covered on its own dedicated
page.
This page is available under the
Creative Commons No Rights Reserved License
Last modified by Ronald Burkey on
2024-12-01